Enhance Your Jobs Feeds with Our New Salary API
Job wrapping process in detail
What is job wrapping?
Job wrapping or job scraping is the process of copying jobs from employer sites or ATSes, converting these jobs to the required format and posting resulting vacancies to a job board database.
Job spider technology downloads (scrapes) all or selected jobs, extracts job content from vacancy pages’ HTML source code, cleans up and improves job content, converts job data into an XML or other job board friendly file format, and synchronizes automatically via recipient job board API.
Step 1. Spider runs job search on employer website and browses job listings
- Spider scrapes all jobs or uses search criteria, i.e. USA location and specific industry category only
- Daily or more frequent spidering runs are scheduled for specific time(s) of day and days of wee
- Resulting job listings are filtered out by keywords in job titles, description, etc.
- Jobs are synchronized: spider downloads new ones, tracks updates and removes expired jobs
Job search form and results listing example:

Step 2. HTML source code is downloaded for each posting and job data is extracted
- Job data content is parsed and converted into plain text or saved as HTML
- Job description HTML tags are cleaned up or replaced, non-desired keywords (i.e. recruiter contacts) are removed
- Parsed locations and categories data is mapped to recipient job board database listings
- Job taxonomy is used to identify missing industry categories
- Job replication is used to create vacancies for additional locations
Job advert example:

HTML source example:

Step 3. Parsed jobs data is saved into XML or CSV file and posted to job board API
- Recipient job board XML or CSV data format is mapped with the job data extracted
- Jobs are synced with target job board(s): new jobs are added, content updates are made and expired jobs are removed
- Jobs posting and API options are: HTTP, SOAP, FTP, Amazon S3 or via email (view all)
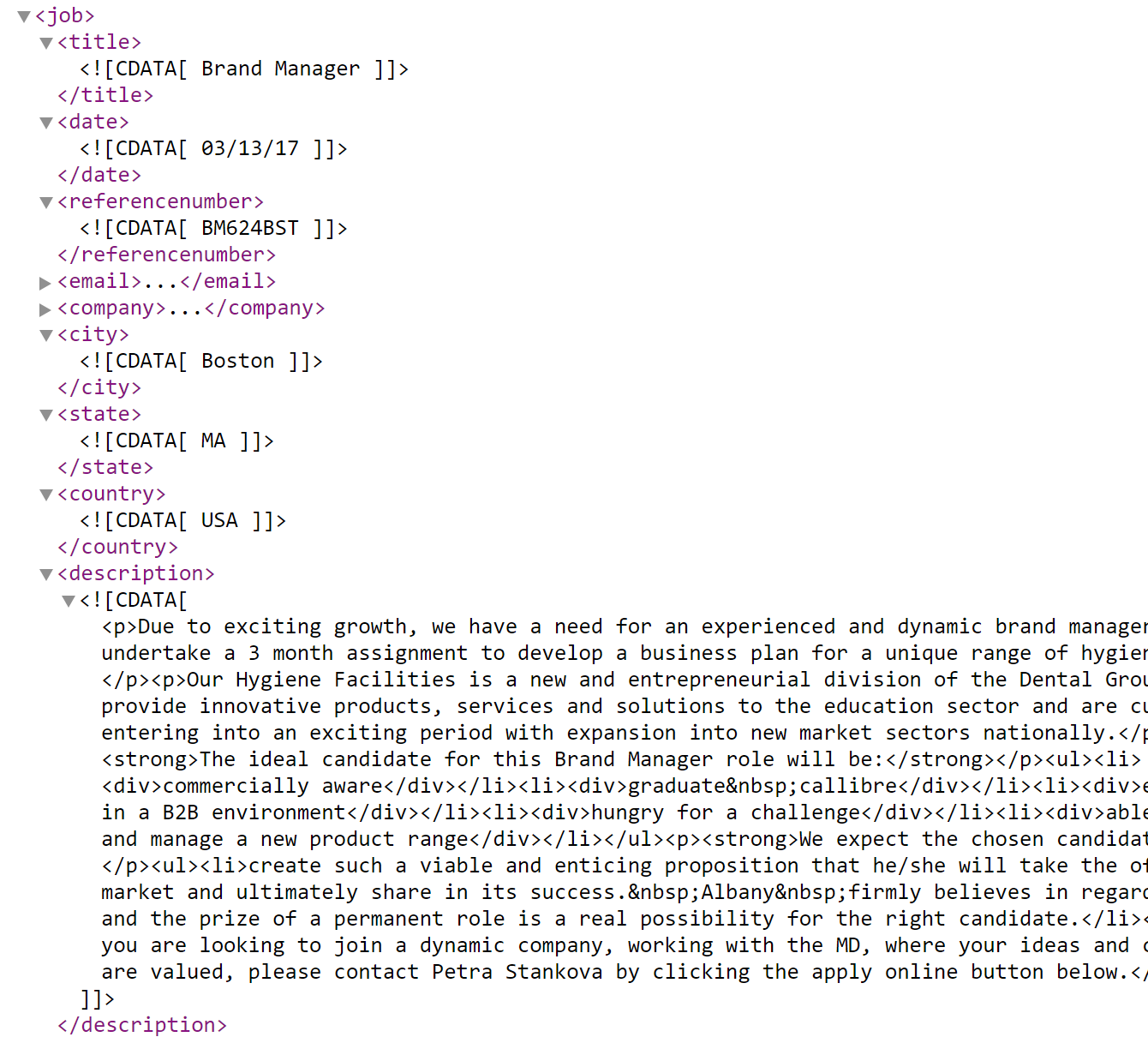
Job XML example (view Jobs XML file):
See also: